racket-mode
Even though it’s been one of my most time-consuming projects, I’ve hardly blogged about racket-mode — an Emacs major mode for Racket. To change that, here’s a post giving an overview of how racket-mode works, as well as a look at how it might grow someday.
Cast of characters
racket-mode consists of two main parts:
-
An Emacs Lisp “front end”. This implements various major and minor modes, the main two of which are:
-
racket-modefor editing.rktfiles -
racket-repl-modefor a REPL
-
- A Racket “back end”. This is a
racketprocess that runs the back end code, which in turn runs your program and implements “commands”, as discussed below.
This mix of Emacs Lisp and Racket code is delivered as an Emacs package (e.g. via MELPA), where the Racket files come along for the ride.1
Crossing the chasm
The Emacs front end (“client”) sends command requests to the Racket back end (“server”) which sends command responses. Exactly how this happens is the aspect of racket-mode that has changed the most over the years.
Historical
The very earliest version of racket-mode was a very thin wrapper around XREPL, which lets you enter commands prefixed by a comma2 like ,enter <filename>. So racket-mode would mostly just comint-send-string a few of these commands (invisibly type them into the buffer on your behalf).
But.
-
What if the user’s program does
readorread-line? If we send commands to the back end, the user’s program will get them. -
Later, command responses became more important. For example, racket-mode’s
racket-describecommand returns HTML (from Racket’s documentation) to be shown in an Emacs buffer. Well, occasionally the HTML might contain something like"\ndiv>"— breaking code trying to read a response up to the next REPL prompt.
Long story short: If you like edge cases, you’ll love multiplexing textual command I/O with user program I/O. That approach is an easy way to start casually. But it’s actually easier long-term to move the command I/O “out-of-band”, when possible. It sucks to demux.
Today
Early Summer 2018 I again changed how command requests and responses work.
The Racket back end starts a TCP “command server”, and the Emacs front end connects to it.
Although the connection method is TCP, the protocol isn’t HTTP. Instead, the command server:
-
Accepts a single TCP connection at a time (multiple requests and responses are sent over the one connection)
-
Uses a subset of valid Emacs Lisp s-expressions for requests and responses.
Command requests are (nonce command param ...).
A thread is spun off to handle each request, so that a long-running command won’t block others. The nonce supplied with the request is returned with the response, so that the client can match the response with the request.3
Command responses are either (nonce 'ok sexp ...+) or (nonce 'error
"message").
Here’s a code snippet to give a rough sense of the commands:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
(match sexpr [`(run ,what ,mem ,pp? ,ctx ,args ,dbg) (run what mem pp? ctx args dbg)] [`(path+md5) (cons (or path 'top) md5)] [`(syms) (syms)] [`(def ,str) (find-definition str)] [`(mod ,sym) (find-module sym maybe-mod)] [`(describe ,str) (describe str)] [`(doc ,str) (doc str)] [`(type ,v) (type v)] [`(macro-stepper ,str ,into-base?) (macro-stepper str into-base?)] [`(macro-stepper/next) (macro-stepper/next)] [`(requires/tidy ,reqs) (requires/tidy reqs)] [`(requires/trim ,path-str ,reqs) (requires/trim path-str reqs)] [`(requires/base ,path-str ,reqs) (requires/base path-str reqs)] [`(find-collection ,str) (find-collection str)] [`(get-profile) (get-profile)] [`(get-uncovered) (get-uncovered path)] [`(check-syntax ,path-str) (check-syntax path-str)] [`(eval ,v) (eval-command v)] [`(repl-submit? ,str ,eos?) (repl-submit? submit-pred str eos?)] [`(debug-eval ,src ,l ,c ,p ,code) (debug-eval src l c p code)] [`(debug-resume ,v) (debug-resume v)] [`(debug-disable) (debug-disable)] [`(exit) (exit)]) |
This approach also makes it reasonably simple for the Emacs Lisp front end to issue some commands “asynchronously”. In fact the lowest-level command function is async:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
(defvar racket--cmd-nonce->callback (make-hash-table :test 'eq) "A hash from nonce to callback function.") (defvar racket--cmd-nonce 0 "Increments for each command request we send.") (defun racket--cmd/async-raw (command-sexpr &optional callback) "Send COMMAND-SEXPR and return. Later call CALLBACK with the response sexp. If CALLBACK is not supplied or nil, defaults to `ignore'." (racket--repl-ensure-buffer-and-process nil) (racket--cmd-connect-finish) (cl-incf racket--cmd-nonce) (when (and callback (not (equal callback #'ignore))) (puthash racket--cmd-nonce callback racket--cmd-nonce->callback)) (process-send-string racket--cmd-proc (format "%S\n" (cons racket--cmd-nonce command-sexpr)))) |
Code that doesn’t need to examine error responses can use a simplified wrapper:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
(defun racket--cmd/async (command-sexpr &optional callback) "You probably want to use this instead of `racket--cmd/async-raw'. CALLBACK is only called for 'ok responses, with (ok v ...) unwrapped to (v ...). 'error responses are handled here." (let ((buf (current-buffer))) (racket--cmd/async-raw command-sexpr (if callback (lambda (response) (pcase response (`(ok ,v) (with-current-buffer buf (funcall callback v))) (`(error ,m) (message "%s" m)) (v (message "Unknown command response: %S" v)))) #'ignore)))) |
Code that needs to wait synchronously for a response can use another wrapper:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(defun racket--cmd/await (command-sexpr) "Send COMMAND-SEXPR. Await and return an 'ok response value, or raise `error'." (let* ((awaiting 'RACKET-REPL-AWAITING) (response awaiting)) (racket--cmd/async-raw command-sexpr (lambda (v) (setq response v))) (with-timeout (racket-command-timeout (error "racket-command process timeout")) (while (eq response awaiting) (accept-process-output nil 0.001)) (pcase response (`(ok ,v) v) (`(error ,m) (error "%s" m)) (v (error "Unknown command response: %S" v)))))) |
In other words, asynchronous is the baseline. Synchronous is the special case where the callback setqs the response and the main Emacs thread polls for it.
What does it mean to “run” a file
The main command is run, which causes it to run a specific .rkt file. “Run” means something similar to what it does in DrRacket: dynamic-require a relative module path and use module->namespace so that you are “inside” the module and can see all its module-level definitions (even those it does not provide). Then it does a read-eval-print-loop, which is the REPL you see in the racket-repl-mode buffer.
Importantly, each run uses a fresh custodian and namespace. Therefore each run discards any changes you made only in the REPL and “resets” you to a namespace corresponding to the .rkt file. In other words, the single source of truth is your source file.
One handy nuance: If, when you run, point4 is inside a submodule at any depth, you enter that submodule. So for example you can put point within a (module+ test ___) form and
C-c C-c. Not only will this run your tests, the REPL will be “inside” the test submodule so you can explore and experiment more. Or you can run a main, or any other, submodule.
Of course there are many wrinkles:
-
In some cases we “instrument” the module to support features like profiling, test coverage, or step debugging.
-
We look for and run
configure-runtimes orget-infos supplied by a#lang. -
We warn when a
#langdoesn’t supply#%top-interaction. -
We load
racket/guilazily. (That way, you don’t get a pointless GUI frame window while working on textual programs.) -
We maybe set up custom print handlers to use pretty-print.
-
If the file contains syntax errors, we try to distill it to a “skeleton” of things that create runtime, module-level bindings, i.e.
requires anddefines. You can think of this as replacing all(define id rhs)with(define id (void)). Why? That way, we get a namespace with the definition identifiers available to things like auto-complete. -
And on and on.
Summer two step
Over the summer of 2018, I added a couple features under the theme of “stepping”.
Macro step expander
A new racket-stepper-mode presents a consistent diff -U 3 format UI for both:
-
expand-once-ing expressions -
whole-file expansion using
macro-debugger/stepper-text(although the UI is not as ambitious as the fantastic macro stepper in DrRacket)
Whole-file expansion potentially can take many seconds. So this is an example where it’s good to have the ability for command responses to come as an asynchronous callback. Emacs isn’t “frozen” while waiting.
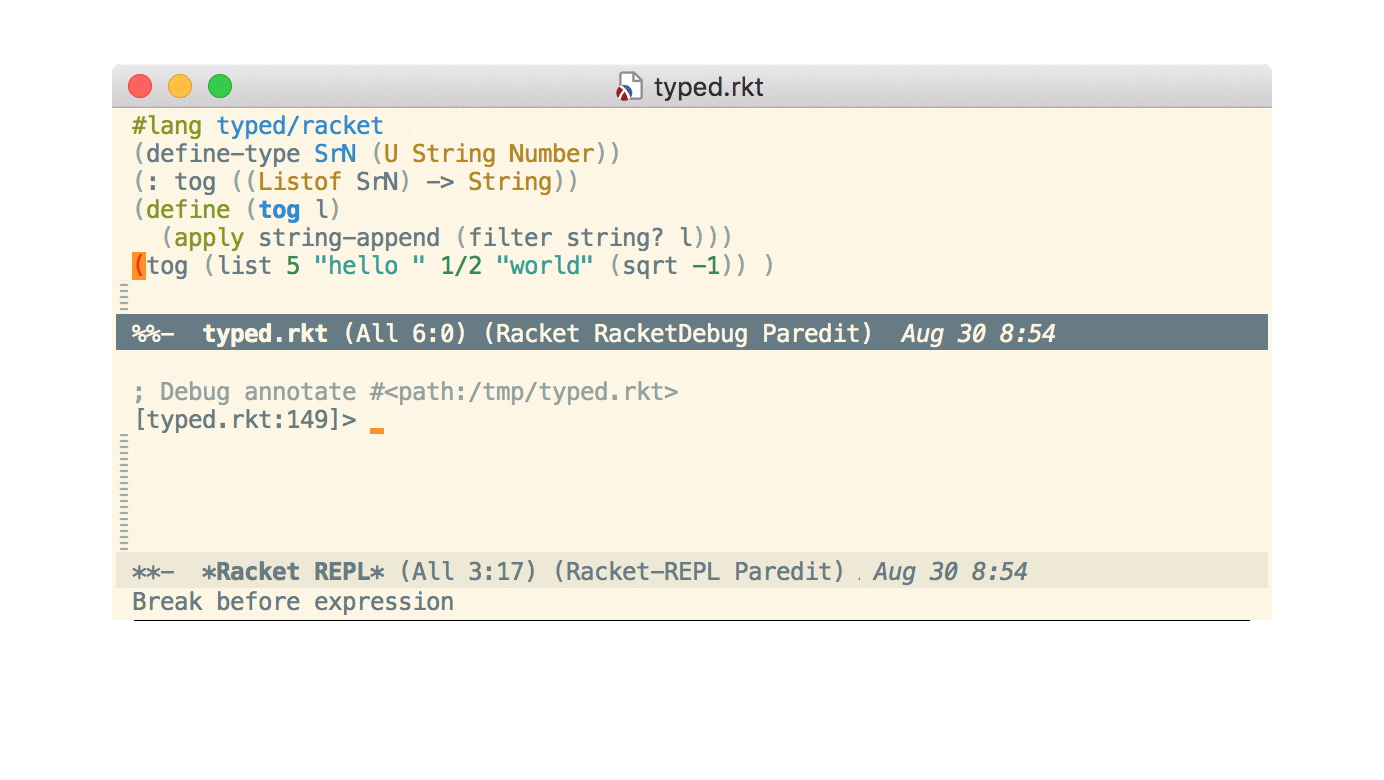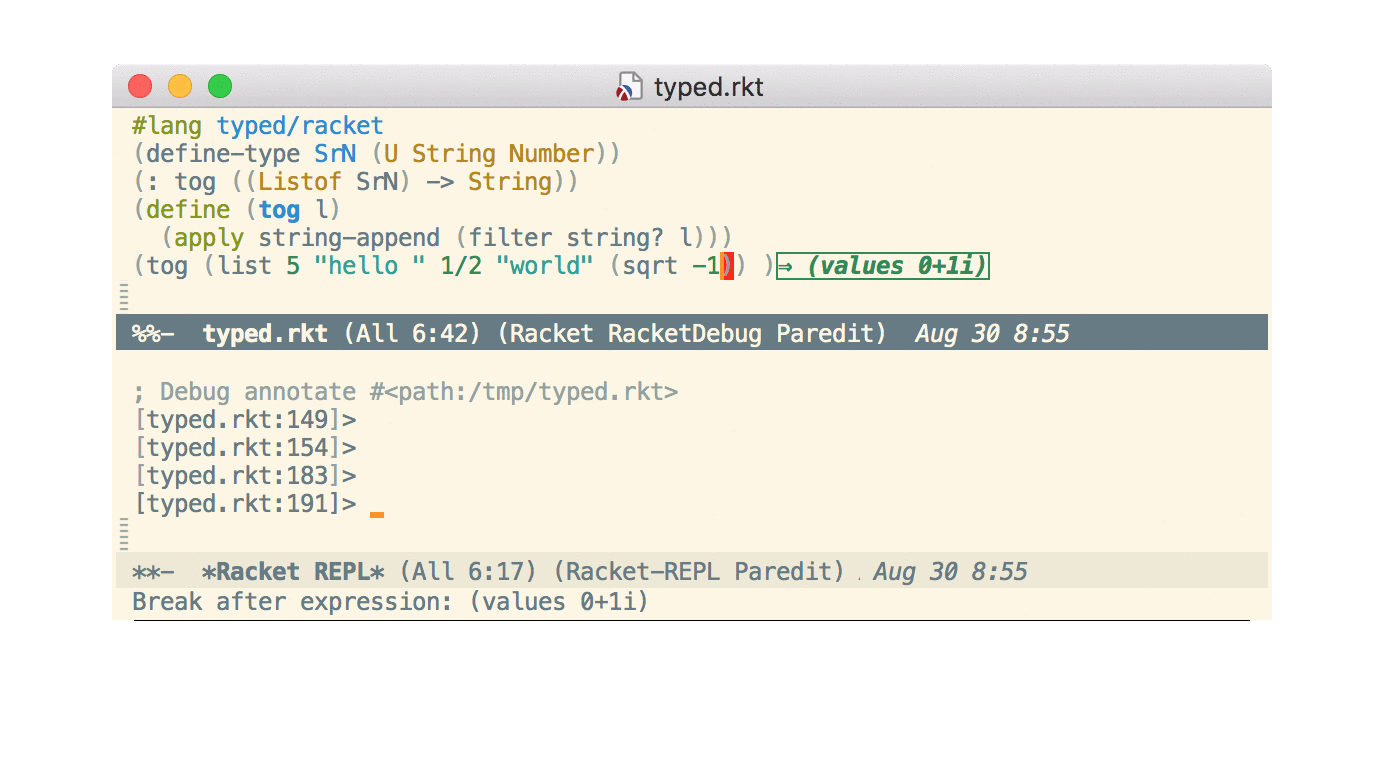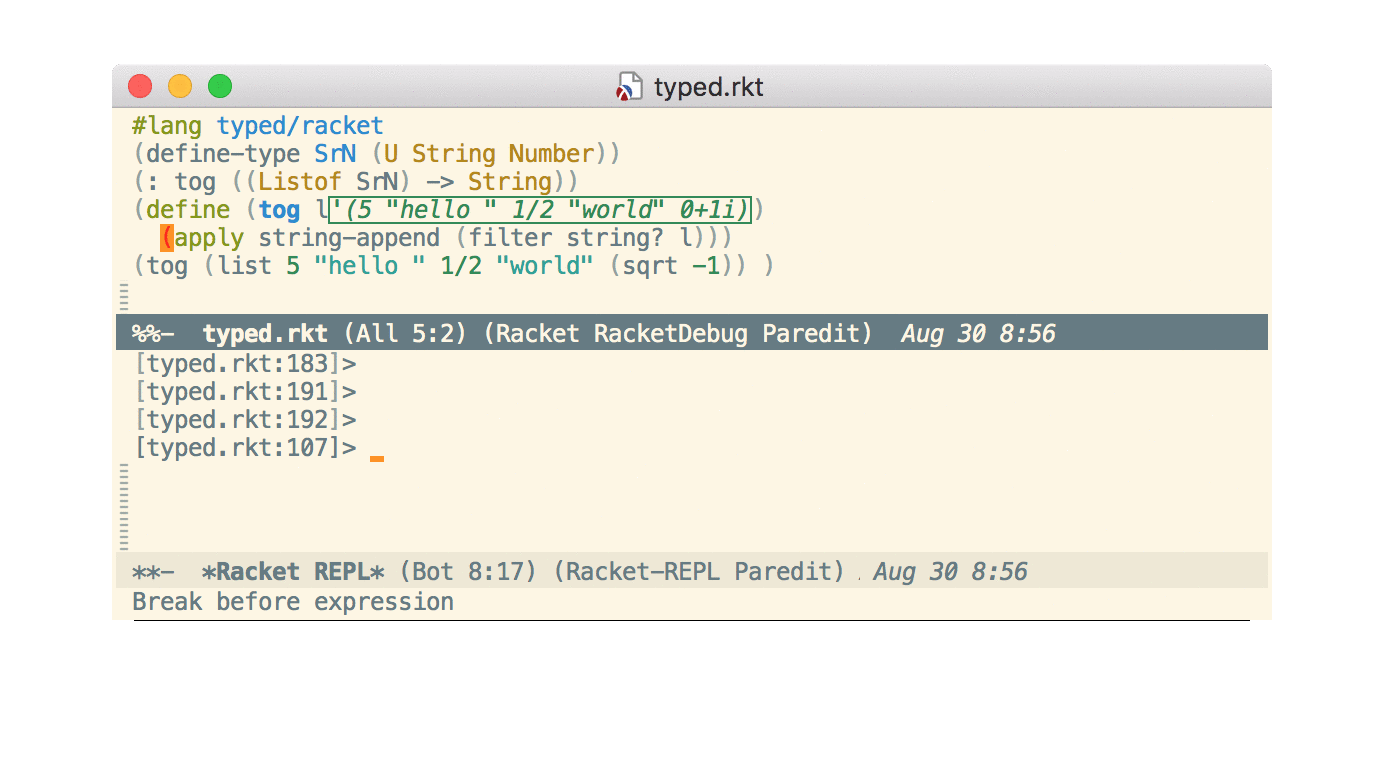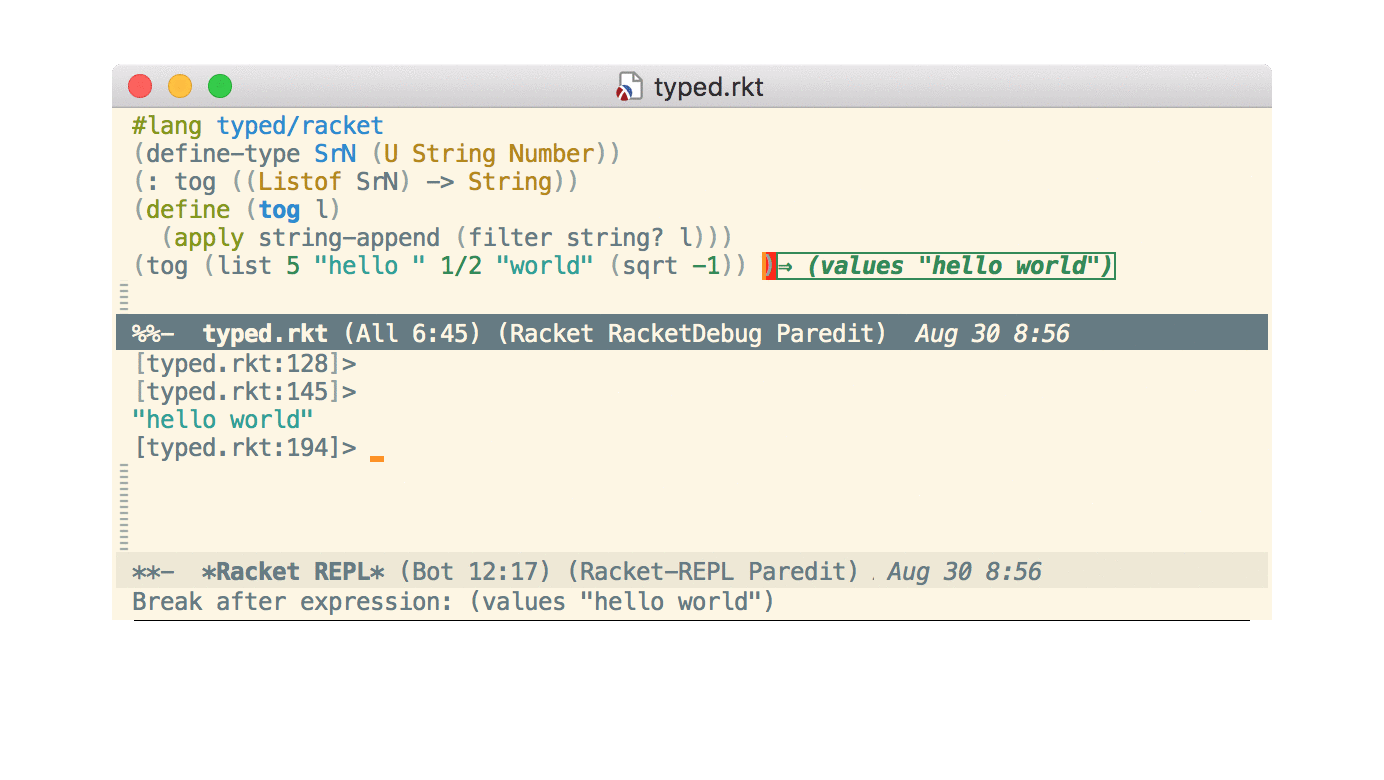
Step debugger
Also new is an interactive step debugger. I won’t repeat the commit message or the documentation here. I’ll just mention that, as the commit message says, I had started to work on this several years ago but decided not to merge it. The new async command protocol was one factor that made it easier. Also, by labeling it “experimental”, I was less worried should it turn out to be too much hassle to support long-term.
I’m curious to see how much people actually use it. I’ve found that I want an interactive debugger much less often writing mostly functional Racket than I did when writing imperative C/C++. With Racket, a step debugger feels more like a nice-to-have than a must-have. Even so, while working in Emacs Lisp for racket-mode, sometimes I have found edebug to be handy. So we’ll see.
Future
Modulo bugs and some UX refinements, I’d say that racket-mode has reached the point where it’s a pretty good "#lang-racket-mode". That is, it’s pretty good for working with s-expression #langs like racket, racket/base, typed/racket, and so on.
However it does not attempt to be a “racket-is-a-programming-language-programming-language-mode” like DrRacket. Maybe that is where it should head next. If so, I’m aware of three main areas, only one of which is done.
Submitted for your approval, in the REPL zone
A #lang may supply a drracket:submit-predicate to say whether some chunk of text is a complete expression. In other words, when a user hits
ENTER in the REPL, should this be sent for evaluation, or, simply insert a newline and wait for them to supply more?
As of a couple months ago, racket-mode does actually look for and use this.
Syntax highlighting
“Font-lock” is what Emacs calls the process of changing the appearance of text — such as syntax highlighting for programming modes. Mostly this is done via regular expressions, although an arbitrary function can be supplied to do both fancier matching and altering.
Traditionally font-lock distinguishes between language elements that are “keywords” vs. “builtins”. When it comes to Racket, this is sort of a weird distinction that I handled ad hoc.
DrRacket takes a different approach. Each #lang may supply a color-lexer. Clearly this is the Correct Way.
And yet. One great way to make Emacs feel sluggish is to do font-lock poorly. To-date, I’ve been worried about the performance of trying to use color-lexers, which are color:text<%> interfaces. How will this perform marshaled over the TCP connection? Will this force racket-mode to use racket/gui always, instead of only when user programs need it?
Indentation
Similarly, racket-mode could someday use a #lang-supplied drracket:indentation — and similarly, naive indentation can bring Emacs to its knees.
Currently racket-mode indents using Emacs Lisp that is mostly hardcoded with special handling for known macros5 in some popular #langs.
I say “mostly hardcoded” because it is extensible in the tradition of lisp-mode and scheme-mode: racket-mode looks for a 'racket-indent-function property on an Emacs Lisp symbol of the same name as the Racket macro. racket-mode sets up some of these itself. You can add your own in your Emacs init file:
1 |
(put 'racket-macro-name 'racket-indent-function indent-value) |
You can also do this using Emacs Directory Variables or in .rkt files using Emacs File Variables. An example of the latter setting up indentation for some sql package syntax:
1 2 3 4 5 6 |
;; Local Variables: ;; eval: (put 'insert 'racket-indent-function 'defun) ;; eval: (put 'update 'racket-indent-function 'defun) ;; eval: (put 'delete 'racket-indent-function 'defun) ;; eval: (put 'select 'racket-indent-function 'defun) ;; End: |
Although this works, it’s not ideal.
So it would be nice for racket-mode to use a #lang-supplied drracket:indentation.
However, even that doesn’t seem enough: Not just a full-blown #lang, but really any library module — like sql — ought to be able to specify indent for special syntax.
So I don’t yet know a good story for rich indentation that is both complete and performant.
Conclusion
Hopefully this gives you some overview of how racket-mode works, as well as what it currently does or does not attempt to do, and why.
-
Another approach would be to split it into an Emacs package and a Racket package. This would have various pros and cons. I think the main disadvantage is that users would need both to update to stay in sync. When using CIDER for Clojure I found this a little troublesome. ↩
-
Since
,is reader shorthand forunquote, which is only valid inside aquasiquote, this is a clever way to distinguish a command from a valid Racket expression. ↩ -
The nonce needn’t be a cryptographically secure random number, just unique; an increasing integer is fine. ↩
-
“Point” is Emacs’ name for what you might call the cursor or caret. ↩
-
As far as I can tell, the convention is that function applications should be indented consistently — only macro invocations might use custom indent. ↩