Using check-syntax in Racket Mode
During most of January and into February, I’ve been working full-time to have Racket Mode make better use of drracket/check-syntax analysis of fully-expanded code. I’m pretty excited by it.
Consider this little Racket program:
1 2 3 4 5 6 7 8 9 10 |
A few things to note:
-
The file module has a side-effecting expression
(push-the-red-button!). Every time the file is evaluated a.k.a. “run”, this expression is evaluated. -
The file module language is
racket/base. -
The submodule
mlanguage istyped/racket/base.
Status quo
Traditionally Racket Mode has required you to racket-run a file in order for some handy features to be available, because it can use the namespace resulting from module->namespace to support those features. This reflects its origins as a wrapper around xrepl. It retained that basic approach even as it grew beyond xrepl.
For instance it uses namespace-mapped-symbols to obtain a list of completion candidates. If it needs to get you documentation, it can synthesize a suitable identifier from a string using namespace-symbol->identifier. It can give such an identifier to xref-binding->definition-tag, and in turn give that result to xref-tag->path+anchor, and get the appropriate help topic.
Likewise the visit-definition feature can use the namespace to make the correct identifier to give to identifier-binding, which tells you where the binding was defined.
Racket Mode lets you run, not just the outermost, file’s module, but specific submodules — the innermost module around point. So when you run the m module, the namespace is inside that submodule. Therefore features work as you’d expect. For example help will be for Typed Racket’s define, and visit-definition will go to the source for that define.
This all works fine, with one drawback: You must racket-run the edit buffer to get results. (And if you make changes, you must run it again to get updated results.) This is a speed bump, especially when exploring many Racket files. It would be nice to open the file, and just visit definitions or get help — without needing to run each file. That can be slow. Worse, what about side-effects like push-the-red-button!?
Also, I knew at least a few people who use Racket Mode pretty much solely as an editing mode. In other words, they use racket-mode to edit .rkt files, but they rarely or never use racket-run and racket-repl-mode. Maybe racket-mode should be simpler and more lightweight — maybe some new minor mode should augment it with the “extras” for those who want them. This is a typical Emacs approach: A major mode handles a basic set of functionality, and one or more minor modes optionally enhance it.
Check Syntax
The Dr Racket IDE has a “Check Syntax” feature, which works solely by expanding a module — but not evaluating a.k.a. “running” it — and analyzing that fully-expanded syntax.
The acronym REPL — read, eval, print, loop? The “E” actually covers a few steps: expand, compile, evaluate. More like “RECEPL”.
A program in fully-expanded form looks like Racket “assembly language”. It is tedious to read, as a human. But a few key forms like define-values, define-syntaxes, and #%require, provide a lot of very useful information about bindings — things defined in that module or imported from another.1
The great news is that the drracket/check-syntax library exposes the analysis Dr Racket does to create annotations for the source buffer. I was able to leverage this to get most of what I wanted to do.
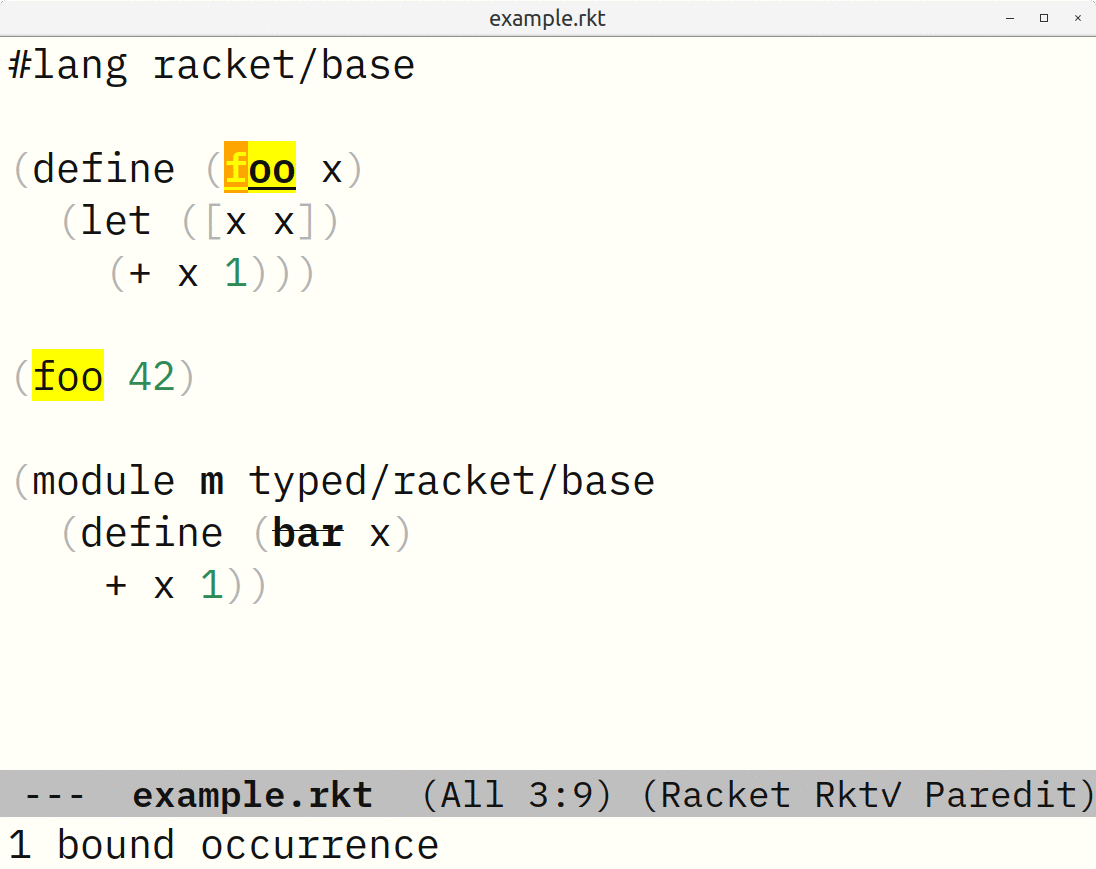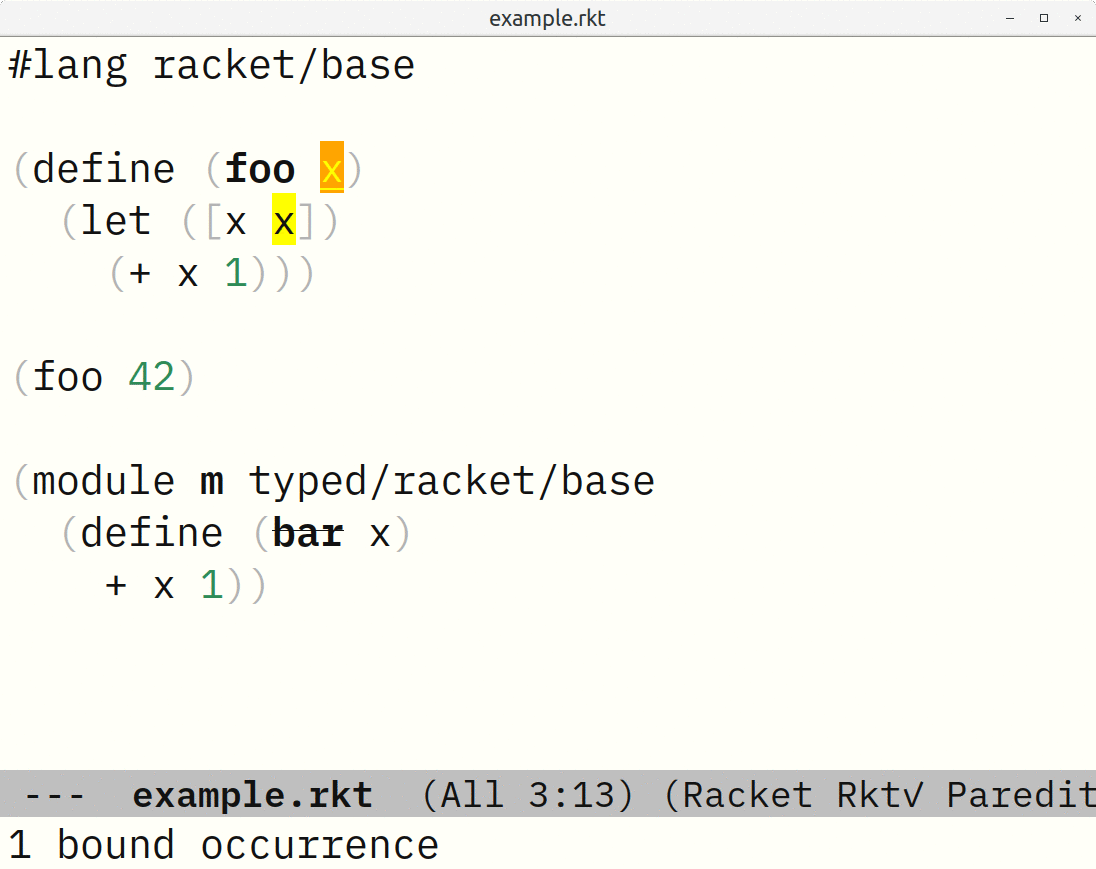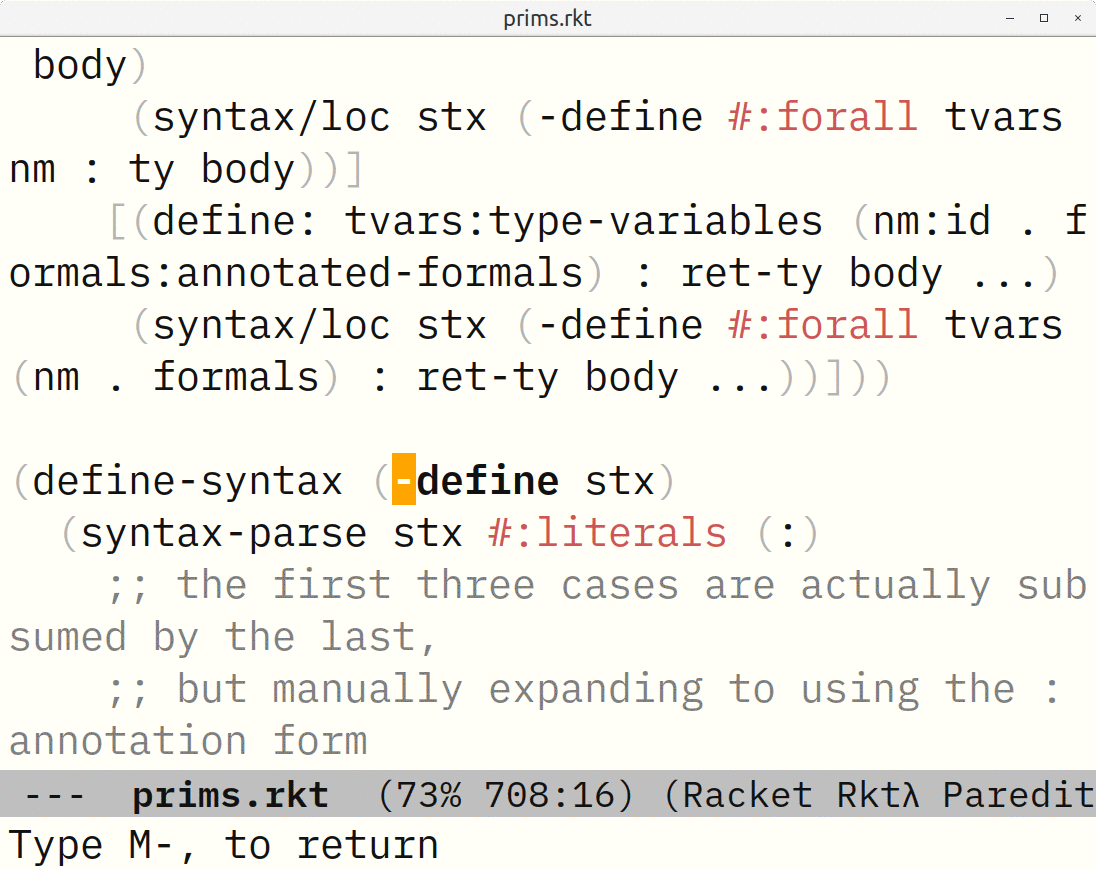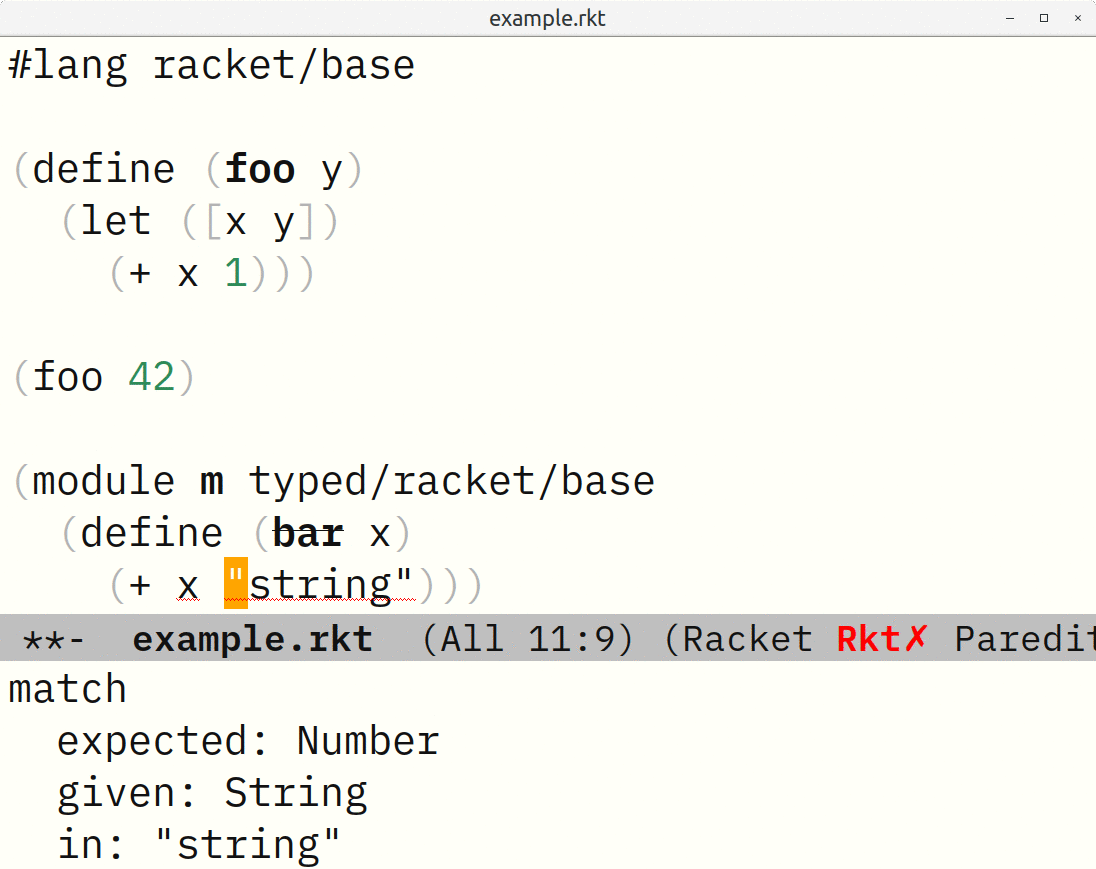
In a few cases, I need to extend this. For example, I wanted all local, module, and imported definitions to be available as completion candidates. The library produces annotations for the arrows Dr Racket draws between definitions and uses. If something is defined but not used? You can’t draw an arrow from something to nothing. Therefore it doesn’t produce an annotation. So the set of definitions in arrow annotations isn’t sufficient. Fortunately there is also a “mouseover text” annotation such as “N bound occurrence(s)”.2 So, a way to get all module and local definitions is to look for all such annotations — those are your definitions. As for imported definitions, I needed to walk the fully-expanded syntax myself, looking for #%require and its subforms that filter and rename what is imported, and do such filters/renames on module->exports lists. Although that didn’t take five minutes to figure out and debug, it wasn’t too bad.
Some of the work involved other issues. By far the slowest part isn’t the analysis of expanded code, it is getting that expanded code: expand can be non-trivial for languages like Typed Racket. For other reasons Racket Mode already maintained a cache of file -> expanded syntax. I needed that to also handle (path-string code-string) -> expanded syntax, for the case of unsaved buffer text. And as a result, I needed to make my own, cache-aware wrapper like show-content around make-traversal.
I also enhanced the back end command server to support the idea of cancelling a command already in progress. That way when we get a new request to analyze updated source, we can cancel any analysis possibly still running for the old, “stale” text.
Front end
How about the “front end”, implemented in Emacs Lisp?
Racket Mode already had a racket-check-syntax-mode minor mode. However it made the buffer read-only. You could navigate, and rename bindings, but you had to quit the mode to resume normal free-form editing. Also it didn’t attempt to unify the UX with normal commands to visit definitions, see help, and so on.
Instead, I wanted to this be something that — as in Dr Racket — runs automatically in the background on a read/write buffer. After you make some changes, and after some short idle delay, a new analysis kicks off. When its results are ready, the buffer annotations and completion candidates are refreshed. Annotations are done using Emacs text properties, and in the case of defs and uses which refer to each other, use Emacs markers so they remain valid after most edits. When there are syntax errors, those are annotated, but previous completion candidates are retained.
Although we can’t draw graphical arrows, we can highlight definitions and uses when point moves over them, using cursor-sensor-mode (which is a minor mode a user can disable if they find this slow or distracting).
Initially I still called this racket-check-syntax-mode. But (a) that’s pretty verbose, and (b) checking your syntax for mistakes is not most of the benefit. Really, it is a static analysis of expanded code that helps you explore and explain. With all those “exp” prefixes, plus an inclination for an even shorter name, I settled on racket-xp-mode.
At this point I’ll simply quote the documentation string for racket-xp-mode and show some screen shots:
racket-xp-mode is an interactive function defined in racket-xp.el.
Documentation
A minor mode that analyzes expanded code to explain and explore.
This minor mode is an optional enhancement to racket-mode edit buffers. Like any minor mode, you can turn it on or off for a specific buffer. If you always want to use it, put the following code in your Emacs init file:
Note: This mode won’t do anything unless/until the Racket Mode back end is running. It will try to start the back end automatically. You do not need to racket-run the buffer you are editing.
This mode uses the drracket/check-syntax package to analyze fully-expanded programs, without needing to evaluate a.k.a. “run” them. The resulting analysis provides information for:
Visually annotating bindings — local or imported definitions and references to them.
Completion candidates.
Defintions’ source and documentation.
When point is on a definition or use, related items are highlighted using racket-xp-def-face and racket-xp-use-face — instead of drawing arrows as in Dr Racket — and “mouse over”. Information is displayed using the function(s) in the hook variable racket-show-functions; it is also available when hovering the mouse cursor. Note: If you find these features too distracting and/or slow, you may disable cursor-sensor-mode. The remaining features discussed below will still work.
You may also use commands to navigate among a definition and its uses, or to rename a local definitions and all its uses.
In the following little example, not only does drracket/check-syntax distinguish the various “x” bindings, it understands the two different imports of “define”:
The function racket-xp-complete-at-point is added to the variable completion-at-point-functions. Note that in this case, it is not smart about submodules; identifiers are assumed to be definitions from the file’s module or its imports. In addition to supplying completion candidates, it supports the ":company-location" property to inspect the definition of a candidate and the ":company-doc-buffer" property to view its documentation.
When you edit the buffer, existing annotations are retained; their positions are updated to reflect the edit. Annotations for new or deleted text are not requested until after racket-xp-after-change-refresh-delay seconds. The request is made asynchronously so that Emacs will not block — for moderately complex source files, it can take some seconds simply to fully expand them, as well as a little more time for the drracket/check-syntax analysis. When the results are ready, all annotations for the buffer are completely refreshed.
You may also set racket-xp-after-change-refresh-delay to nil and use the racket-xp-annotate command manually.
The mode line changes to reflect the current status of annotations, and whether or not you had a syntax error.
If you have one or more syntax errors, use the standard next-error command and key bindings to navigate among them. Although most languages will stop after the first syntax error, some like Typed Racket will try to collect and report multiple errors.
Tip: This mode follows the convention that a minor mode may only use a prefix key consisting of “C-c” followed by a punctuation key. As a result, racket-xp-control-c-hash-keymap is bound to “C-c #” by default. Although you might find this awkward to type, remember that as an Emacs user, you are free to bind this map to a more convenient prefix, and/or bind any individual commands directly to whatever keys you prefer.
C-c # . racket-xp-visit-definition C-c # g racket-xp-annotate C-c # j racket-xp-next-definition C-c # k racket-xp-previous-definition C-c # n racket-xp-next-use C-c # p racket-xp-previous-use C-c # r racket-xp-rename C-c C-. racket-xp-describe C-c C-d racket-xp-documentation M-. racket-xp-visit-definition
Keep in mind that almost everything can be customized using defined faces or variables. Information like “1 bound occurrence” or error messages can be configured to be shown using the echo area (as in these screen shots), a header line, a pos-tip tooltip, and/or whatever custom function you want to supply.3
It was particularly fun when things were working well enough that I could use racket-xp-mode to more quickly explore and better understand some of the drracket/check-syntax code — as well as my own.
Taking stock
What remained was to step back and look at the racket-mode major mode (in hindsight maybe better-named racket-edit-mode), now optionally enhanced by racket-xp-mode, as well as the racket-repl-mode major mode.
What should live where, what should change, and what should remain the same?
After all, the old way of using the namespace from a run program, is actually still useful and quite appropriate for the REPL. You can run a program, then go into the REPL, and define and require all sorts of things. It still makes send to have that live namespace answer questions like “What are your symbols for completion candiates?” or “Which define is this, exactly, and where is its help or definition source?”. It is nice that you no longer must run your program, but if you have run it, and you’re in the REPL buffer… when in Rome.
So I realized there were a few commands — visit-definition, describe, help, completions — where there should be two flavors. One provided by racket-xp-mode and another provided by racket-repl-mode still working the “old” way. For example the old racket-visit-definition is effectively just moved/renamed to racket-repl-visit-definition.
At a lower level, also, there were some functions where I wrapped both flavors in a single back end command with a “how” argument: Use the current-namespace from module->namespace, or, use the namespace and module lexical context for some given path? (The latter covers cases where there exists no annotation, or the user has typed some arbitrary text, and we want to synthesize an identifier.)
Automatically starting the back end
One other note. Racket Mode consists of an Emacs front end, obviously, and also a back end command server written in Racket. Although racket-xp-mode does not need to racket-run any .rkt buffer, it does need to talk to the back end server. Today that still means that a racket-repl-mode buffer is created. It just stays in the background, and it needn’t be running any particular file — but it must be open.4
When racket-xp-mode needs the back end, it will try to start it if not already running. This made me nervous, because auto-starting in the past led to some bugs, especially when something needed a command response to continue: Emacs could sometimes get stuck at a “starting…” or “waiting for…” message. You could
C-g out of that, usually. But it sucked. I had a think and realized the key was to make everything “asynchronous” with explicit continuations. I’d already replaced many uses of racket--cmd/await with racket--cmd/async — which takes a completion callback a.k.a. continuation procedure. I replaced even more. And also, I realized that starting the command server should itself be asynchronous. And so any racket--cmd/async that can’t happen yet, is pushed onto a list of continuations to be run eventually by the “connected to command server” continuation when it is called. Meanwhile, Emacs remains unblocked. Although I am not going to jinx this by declaring “mission accomplished!”, and some bugs may lurk, I’ve tried to be diligent in thinking through race conditions. I feel like this approach at least simplifies what needs to be considered.
Availability
As I write this, I have 100+ commits still on a check-syntax branch — not yet merged to master or available from MELPA.
If you’re feeling brave or curious, feel free to try it out! I’ve been dogfooding it a fair amount. I’m still finding and fixing edge cases, but I think it’s stable enough to understand the basic experience.
-
The outermost
moduleform also gets a syntax-property with the lexical context inside the module, including imports. As a result, you can synthesize an identifer using that as the first argument todatum->syntax, and then do the same things with that identifier you could with one fromnamespace-symbol->identifer, in order to support features like visit-definition or help, where the user has supplied some arbitrary string. ↩ -
And if you want to find unused imported and locally-defined definitions, they’ll have a “mouseover” annotation, “no bound occurrences”. ↩
-
It’s also shown when you hover the mouse pointer. If you use a mouse with Emacs, I won’t judge you. *coughs*. ↩
-
Perhaps in the future that will change — especially if Racket Mode ever supports multiple REPLs open at once. In that case, starting the back end will be an independent first step, things like
racket-runwill create one or more REPLs, and the I/O for the comint buffers will be a network stream instead of stdin/stdout. ↩